Why Do We Need Evaluators?
LLM agents are more complex than single-turn completions. They operate across multiple steps, use tools, and depend on context and external systems like memory or APIs. This complexity introduces new failure modes: agents may hallucinate tools, get stuck in loops, or produce final answers that hide earlier mistakes. Evaluators make these issues visible by checking correctness, relevance, task completion, tool usage, memory retention, safety, and style. They ensure outputs remain consistent even when dependencies shift and provide a structured way to measure reliability. Evaluation is continuous, extending into production through automated tests, drift detection, quality gates, and online monitoring. In short, evaluators turn outputs into trustworthy systems by providing measurable and repeatable checks that give teams confidence to deploy at scale.Evaluators types
The system supports:- Custom evaluators - Create your own evaluation logic tailored to specific needs
- Built-in evaluators - pre-configured evaluators by Traceloop for common assessment tasks
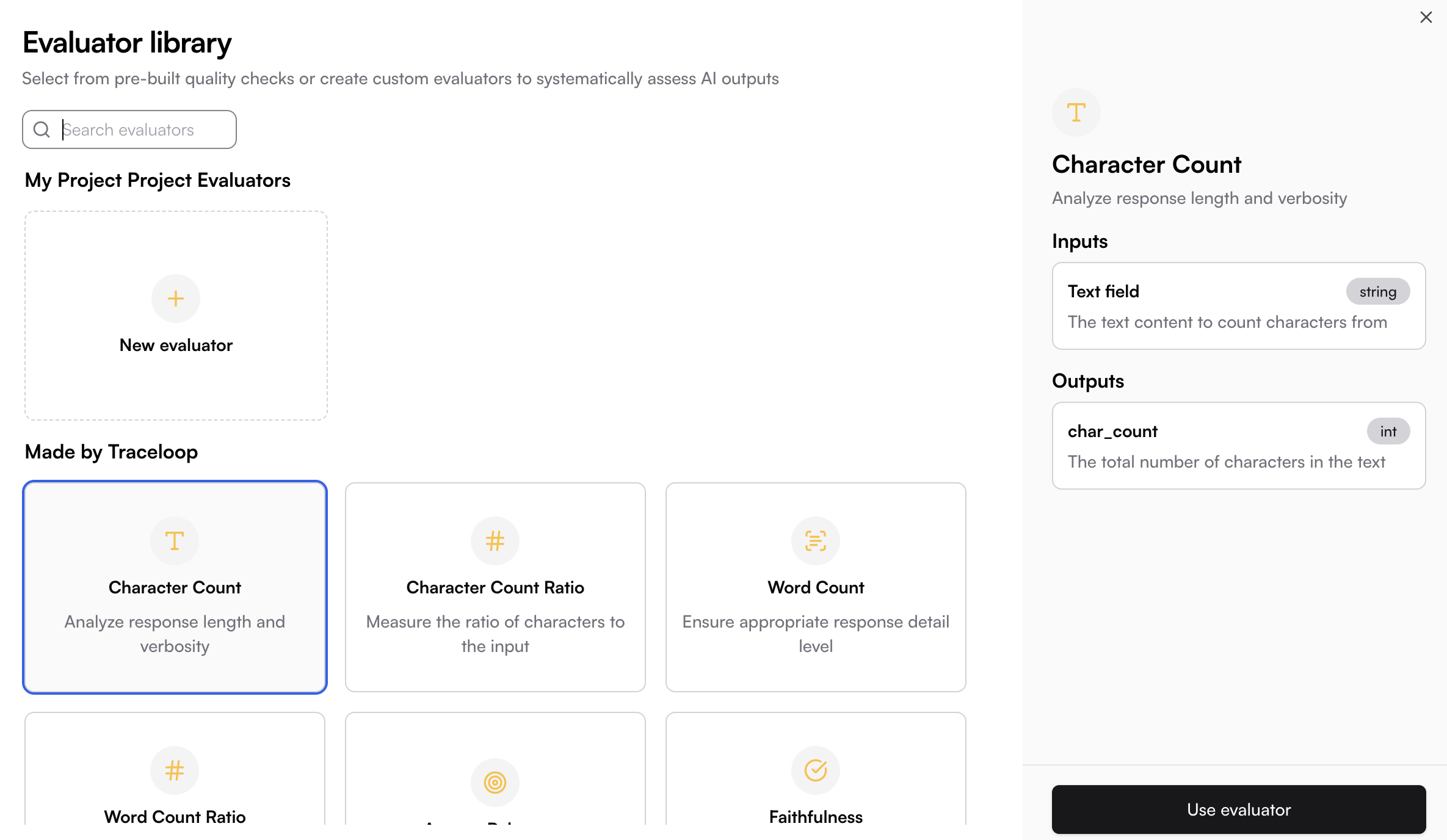
Where to Use Evaluators
Evaluators can be used in multiple contexts within Traceloop:- Guardrails - Apply evaluators in real-time as inline safety checks and quality gates that run synchronously with your application code to prevent issues before they reach users
- Playgrounds - Test and iterate on your evaluators interactively, compare different configurations, and validate evaluation logic before deployment
- Experiments - Run systematic evaluations across datasets programmatically using the SDK, track performance metrics over time, and easily compare experiment results
- Monitors - Continuously evaluate your LLM applications in production with real-time monitoring and alerting on quality degradation